Notions de base
Quels mécanismes sont mis en oeuvre dans le surf ?
HTTP est donc un protocole somme toute assez simple par lui même. Ce qui complique la compréhension de l'ensemble des processus mis en oeuvre, c'est toute " l'intelligence " qui est ajoutée, tant du côté serveur que du côté client.
Au départ, un client envoie une requête à un serveur HTTP et celui-ci y répond. Toute la difficulté vient de deux aspects qui sont indépendants du protocole HTTP lui-même :
- Le traitement de l'information pratiqué par le serveur avant d'envoyer le résultat de la requête.
- Le traitement de l'information pratiqué par le client avant d'afficher le résultat de la requête.
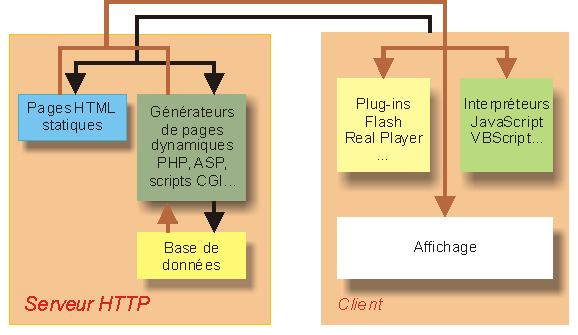
Côté serveur
Lorsqu'une requête arrive sur le serveur, elle peut concerner :
- Une simple page HTML "statique" (le cas de cette page par exemple). Tout son contenu est déjà défini en HTML et le serveur n'a qu'à l'envoyer, tel quel, au client. Dans cette configuration, un site web est fortement ressemblant au contenu d'un livre, il est écrit une fois pour toutes. Toute modification doit faire l'objet d'une réédition.
- Une page HTML dont certains éléments sont "dynamiques", c'est-à-dire qu'ils sont construits à partir de sources d'informations diverses au moment de l'envoi au client. Ces méthodes ont pour but de produire deux fournitures d'informations typiquement impossibles à réaliser simplement avec des pages purement statiques:
- Des informations qui sont le résultat d'un calcul à partir d'éléments que le client a transmis au serveur dans sa requête.
- Des informations issues d'une base de données mise à jour par un moyen quelconque. Ces informations peuvent évoluer à tout instant et leur affichage via HTTP nécessite leur intégration en temps réel dans le document.
- On peut bien entendu imaginer un document dont le contenu intègre les deux exercices précédents.
Plusieurs possibilités existent pour réaliser de telles opérations :
- Les exécutables CGI (Common Gateway Interface).
Ces exécutables construisent intégralement un flux HTML au moment de leur appel. Cette technique, la plus ancienne, n'est pas forcément la meilleure. Les exécutables peuvent être écrits dans un langage compilé comme le C ou dans un langage interprété comme le Perl, ce qui est le plus souvent le cas. L'exécutable est déroulé sur le serveur lui-même (ou sur un autre, mais ce n'est qu'un détail). - Des langages plus "spécialisés" comme PHP ou ASP.
Active Server Pages est une technologie Microsoft, alors que Personal Home Page est une technologie libre. Les deux sont sensiblement identiques au niveau des concepts, mais pas de la syntaxe.
Ces technologies sont dites "Server Side", c'est à dire que les traitements sur l'information sont effectués sur le serveur.
L'avantage du "server side" est que le code HTML reçu par le client est du HTML pur, ce qui veut dire qu'à priori, tout navigateur peut l'afficher correctement, sans trop de précautions particulières de la part de l'auteur du site.
L'inconvénient est que le serveur voit sa charge augmenter dans des proportions qui peuvent être considérables et qu'en cas de connexion lente, la navigation devient vite pénible, lorsqu'il y a beaucoup de traitement d'informations introduites par le client, comme des calculs exécutés à partir de données issues d'un formulaire.
Côté client
De ce côté là aussi, des traitements d'informations peuvent être utiles :
- Contrôler par exemple la validité des informations saisies dans un formulaire, avant de les envoyer au serveur. Ca évite des allers-retours inutiles en cas de saisie erronée.
- Effectuer un traitement local de certaines informations pour afficher un résultat. Un exemple serait d'inclure une calculette dans une page web, cette calculette travaillant uniquement chez le client, sans jamais rien envoyer au serveur.
- Réaliser toutes sortes d'opérations susceptibles de rendre les pages visitées plus vivantes, en introduisant des animations, des menus déroulants et toutes sortes de "gadgets" propres à égayer (de façon plus ou moins heureuse) une page web.
Là encore, les données peuvent être traitées, de diverses manières.
- Les JavaScripts.
Ces petits applicatifs, transmis dans le document HTML, sont exécutés côté client par le navigateur. Malheureusement, chaque navigateur a une notion plus ou moins personnelle de l'interprétation de JavaScript et c'est un véritable casse-tête pour le concepteur que d'écrire des scripts qui fonctionnent sur la totalité des navigateur existants, même si un effort de standardisation a été entrepris sur les dernières versions (Internet Explorer 5 et plus, Netscape 6 et plus, Mozilla... Mais il en existe beaucoup d'autres). - Les VBScripts.
C'est la même philosophie que pour le JavaScript, à part que c'est du Visual Basic, propriété de Microsoft, qui ne fonctionne donc que sur Internet Explorer. Si la solution est intéressante dans un Intranet, où l'on maîtrise l'installation des postes clients, elle devient inexploitable sur l'Internet. - Les composants ActiveX qui sont des exécutables compilés, qui ne peuvent s'exécuter eux aussi que dans Internet Explorer, c'est également une technologie propriétaire de Microsoft. Très intéressante sur le principe, elle n'est en pratique utilisable de façon acceptable que sur un intranet.
- Les applets Java qui sont comparables aux composants ActiveX, mais qui ont des chances de s'exécuter correctement sur tout navigateur, si une machine virtuelle Java est installée. Ces deux technologies présentent malheureusement de gros risques de sécurité.
- Les "plug-in"
Ce sont des composants enfichables qui étendent les possibilités intrinsèques des navigateurs, comme l'affichage de documents "flash" par exemple.
Les avantages sont de deux sortes :
- Tout traitement de données réalisé localement est rapide et sans surcharge pour le serveur.
- Les effets d'animation, comme les menus déroulants ou les bandeaux défilants ne peuvent être que réalisés localement.
Les inconvénients viennent des incompatibilités entre navigateurs et des trous de sécurité introduits par des exécutables téléchargés sur le client, issus d'origines qui peuvent être malveillantes.
Il n'est pas forcément aisé pour un surfeur de faire précisément la part des choses dans tous ces mécanismes qui peuvent se combiner avec plus ou moins de complexité (et de bonheur) au fil des sites visités.
Pour vous aider à mieux vous y retrouver, des exemples simples sont donnés plus loin.
Quelques notions supplémentaires
Le codage MIME
(Multipurpose Internet Mail Extension. Format de messages de l'Internet permettant de découper un message en plusieurs parties et d'y inclure des données non-ASCII, à savoir du son, des images..)
Définition empruntée au "Jargon Français".
HTTP, un peu comme SMTP, ne sait pas nativement transporter autre chose que du texte. Il est bien connu de tous que le web propose aussi autre chose, comme des images (jpg, gif, png...), des animations et des documents aux formats plus ou moins particuliers (pdf, mpg, doc, xls...). Client et serveur doivent se mettre d'accord sur un moyen de coder ces information (serveur) et de les décoder (client) pour les afficher quand c'est possible, ou en proposer le téléchargement. Dans tous les cas, ces données non textuelles doivent être codées et décodées de façon cohérente.
Les cookies
Les cookies ne sont pas une mauvaise invention, c'est leur utilisation qui est parfois détournée à des fins perversement contestables.
Contrairement à ce que l'on peut penser, Il n'existe pas de mémoire dans la navigation web. Plus exactement, la notion de "session" n'existe pas (mais ça vient). Pour bien comprendre, prenons un exemple simple : Vous entrez sur un site privé qui nécessite une authentification (nom d'utilisateur et mot de passe) A priori, sans l'aide des cookies, vous serez probablement amené à vous identifier à chaque nouvelle page.
Le principe est simple : Une fois authentifié, le serveur va déposer chez vous un "cookie" contenant des informations qu'il peut ensuite aller relire à chaque ouverture d'une nouvelle page, pendant toute la durée de vie de ce cookie.
Normalement, il n'y a que le serveur qui a déposé un cookie qui peut aller le relire (éventuellement un autre serveur du même domaine). Malheureusement, certains ont trouvé des moyens pour extorquer aux clients des cookies dont ils ne sont pas à l'origine.
Le passage par un proxy
Nous allons profiter de l'occasion pour tordre le cou à une confusion trop souvent répandue entre deux méthodes qui permettent toutes deux l'accès au Net pour un réseau local :
- Le routeur NAT d'un côté.
Le routeur NAT agit au niveau IP. Il fonctionne pour tous les protocoles applicatifs comme HTTP, FTP, mais aussi POP, IMAP, SMTP etc. (voir les chapitres dédiés : IP Masquerade et Netfilter). - Le proxy de l'autre.
Le serveur proxy travaille, lui, au niveau du protocole applicatif lui-même. Un serveur proxy n'assure aucun routage au niveau IP. En français, on appelle ça un serveur mandataire.
Pour l'exemple nous mettrons en oeuvre un serveur proxy libre sous Linux : le très célèbre SQUID. Comme, à l'usage, je constate que ce site sert quelquefois de "mode d'emploi", nous en profiterons pour développer un peu la mise en oeuvre de ce serveur.